Zestawy zadań

Zawartość:
Zestaw 0
Proszę zaimplementować typ danych setSimple
reprezentujący matematyczny zbiór oraz operacje które dla dwóch zbiorów
\(A\), \(B\) realizują:
- sumę zbiorów \(A \cup B\)
- część wspólną zbiorów \(A \cap B\)
- różnicę zbiorów \(A - B\)
- sprawdzanie identyczności zbiorów \(A \equiv B\)
oraz dla elementu \(x\) i zbioru \(A\) realizują:
- wstawianie \(x\) do zbioru \(A\)
- usuwanie \(x\) ze zbioru \(A\)
- sprawdzanie czy \(x \in A\)
Proszę założyć, że istnieje skończona liczba \(N\) możliwych elementów. Można sobie na
przykład wyobrazić, że wszystkie rozpatrywane przez nas zbiory są
podzbiorami pewnego zbioru \(\Omega\)
zawierającego \(N\) elementów. Dzięki
takiemu założeniu implementacja każdego z rozpytywanych zbiorów może być
oparta na jednowymiarowej tablicy o rozmiarze \(N\). Każdy index \(i = 1 \ldots N\) (lub \(i = 0 \ldots N-1\)) tej tablicy
odpowiadałby jednemu z elementów \(\Omega\). Wartość przechowywana w tablicy
pod indeksem \(i\) (lub \(i - 1\)) wskazuje na to czy dany element
należy (np. true , 1) do rozpatrywanego zbioru
czy nie (np. false , 0).
- Implementacje proszę wykorzystać w programach, które badają złożoność obliczeniową poszczególnych operacji.
- Proszę opisać podejście wykorzystane do badania złożoności obliczeniowej. Jak wygląda zależność czasu wykonania od rozmiaru problemu. Jak to się ma (czy to się ma) do teoretycznej złożoności obliczeniowej?
- Proszę przetestować działanie wszystkich operacji:
- wystarczy wyniki testów wypisywać na standardowe wyjście
- nie trzeba korzystać z systemów do unit testów
- W większości zadań nie jest określony typ danych elementów zbioru. Można korzystać na przykład z liczb całkowitych. Nie powinno mieć to większego znaczenia jeżeli pewne warunki są spełnione. Jakie to warunki?
- notacja \(O\), uwaga w poniższych linkach dla niektórych przypadków są inne wyniki, proszę się zastanowic, która informacja jest prawidłowa:
- prosty przykład
Zestaw 1
Proszę zaimplementować typ danych setLinked
reprezentujący matematyczny zbiór oraz wszystkie operacje z zadania
A. Tym razem w implementacji proszę wykorzystać
posortowane listy łączone.
Korzystając z wyników zadań A oraz B proszę się zastanowić która implementacja jest lepsza i w jakiej sytuacji. Uwaga: to zadanie może być zaliczone pod warunkiem prawidłowego wykonania A oraz B.
Proszę zaimplementować typ danych będący uproszczoną wersją zbioru, posiadającą jedynie trzy operacje:
- wstawianie \(x\) do zbioru \(A\)
- usuwanie \(x\) ze zbioru \(A\)
- sprawdzanie czy \(x \in A\)
Tym razem w zbiorze przechowywane będą ciągi znaków o długości \(50\). W implementacji proszę wykorzystać jednowymiarową tablicę, której elementy są ciągami znaków.
- Implementacje proszę wykorzystać w programach, które badają złożoność obliczeniową poszczególnych operacji.
- Proszę opisać podejście wykorzystane do badania złożoności obliczeniowej i skonfrontować Państwa wyniki z oczekiwaniami teoretycznymi.
- Proszę przetestować działanie wszystkich operacji:
- wystarczy wyniki testów wypisywać na standardowe wyjście
- nie trzeba korzystać z zaawansowanych systemów do unit testów
- W większości zadań nie jest określony typ danych elementów zbioru. Można korzystać na przykład z liczb całkowitych. Nie powinno mieć to większego znaczenia jeżeli pewne warunki są spełnione. Jakie to warunki?
- notacja \(O\), uwaga w poniższych linkach dla niektórych przypadków są inne wyniki, proszę się zastanowic, która informacja jest prawidłowa:
- prosty przykład z posortowanymi listami łączonymi
Zestaw 2
Implementacja zbioru wykorzystująca jednowymiarowe tablice o skończonym rozmiarze z zadania A w zestawie 0 zakłada, że każdemu elementowi zbioru można przypisać liczbę naturalną \(1 \ldots N\). Proszę zaimplementować funkcje implementujące takie przyporządkowanie dla zbiorów:
- liczb całkowitych \(n , n + 1 , n + 2 , \ldots , m\) gdzie \(n < m\)
- liczb całkowitych \(n , n + 2 , n + 4 , \ldots , m\) gdzie \(n < m\)
- liter \(a , b , c , \ldots , z\), bez polskich znaków ęóąśłżźć
- dwuliterowych napisów, gdzie każda litera jest z zakresu \(a - z\) bez polskich znaków ęóąśłżźć
Proszę zaimplementować typ danych setHashed
reprezentujący matematyczny zbiór oraz operacje które dla dwóch zbiorów
\(A\), \(B\) realizują:
- sumę zbiorów \(A \cup B\)
- część wspólną zbiorów \(A \cap B\)
- różnicę zbiorów \(A - B\)
- sprawdzanie identyczności zbiorów \(A \equiv B\)
oraz dla elementu \(x\) i zbioru \(A\) realizują:
- wstawianie \(x\) do zbioru \(A\)
- usuwanie \(x\) ze zbioru \(A\)
- sprawdzanie czy \(x \in A\)
Tym razem proszę wykrzystać następujący sposób hashowania:
- Każdy z elementów \(x\) wpada do jednego z \(N\) “kubełków”.
- Każdy “kubełek” zawiera zbiór zaimplementowany z wykorzystaniem posortowanej listy łączonej.
- Jeżeli założymy, że wrzucamy liczby całkowite, numer “kubełka” do którego wpada \(x\) jest określony przez resztę z dzielenia \(mod(x , N)\).
Przykład dostępny jest tutaj. Państwa implementację proszę wykorzystać w programie, który bada złożoność obliczeniową poszczególnych operacji. Dla każdej z zaimplementowanych operacji program powinien produkować jeden plik, który może być uruchomiony z wykorzystaniem programu gnuplot. W wiadomości e-mail proszę opisać podejście wykorzystane do badania złożoności obliczeniowej i skonfrontować Państwa wyniki z wartościami teoretycznymi.
Korzystając z wyników zadań A oraz B z zestawu 1 oraz zadania B z obecnego zestawu proszę się zastanowić która implementacja jest lepsza i w jakiej sytuacji. Swoją odpowiedź (popartą odpowiednimi wykresami) proszę przesłać za pośrednictwem e-mail.
Aby ułatwić Państwu zadanie, proszę założyć, że elementami przechowywanymi we wszystkich zbiorach są słowa składające się z 4 liter (bez polskich znaków). Można wykorzystać zadanie A.
- Dla każdej implementacji typu danych oraz dla każdej
zaimplementowanej operacji proszę dodatkowo:
- zamieścić w Państwa programie test sprawdzający czy operacje są zaimplementowane prawidłowo
- aby ułatwic Państwu pracę możemy się umówić, że w teście będzie sprawdzana niewielka ilość przypadków - na tyle mała aby można było je wypisać na ekranie komputera i przeanalizować
- Badając złożoność obliczeniową operacji, proszę się zastanowić jak powina wyglądać zależność \(t(n)\) czasu wykonania problemu (\(t\)) od rozmiaru problemu (\(n\)) i nanieść tą hipotezę na odpowiedni wykres. Wystarczy jeden wykres dla wybranej operacji w danym problemie.
- Kilka wykresów dla zadania B z różną liczbą “klas” albo “porcji” na które może wskazywać funkcja haszująca: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, …, 100
- W większości zadań nie jest określony typ danych elementów zbioru. Można korzystać na przykład z liczb całkowitych. Nie powinno mieć to większego znaczenia
Zestaw 3
Proszę zaimplementować typ priorotyQueue będący oparty
na matematycznym zbiorze i posiadający, dla słownika \(A\) oraz elementu \(x\), operacje:
- wstawianie elementu \(x\) do kolejki \(A\)
- zwracanie i jednocześnie usuwanie elementu o najmniejszym “priorytecie” z kolejki \(A\)
Niech \(p(x)\) będzie funkcją zwracającą “priorytet” elementu \(x\). Jeżeli w słowniku przechowywane będą liczby całkowite, priorytetem może być identyczność - \(p(1) = 1\), \(p(2) = 2\), …
Państwa implementację proszę oprzeć na wybranej, omawianej wcześniej, implementacji zbioru. Proszę zbadać złożoność obliczeniową operacji usuwania z kolejki elementu o najmniejszym “priorytecie” (wykres, wartość teoretyczna, dyskusja).
Proszę zaimplementować kolejkę priorytetową
priorityQueueBinary z operacjami jak w zadaniu
A ale tym razem proszę oprzeć swoją implementacje o
kopiec binarny. Proszę zbadać złożoność obliczeniową operacji usuwania z
kolejki elementu o najmniejszym “priorytecie” (wykres, wartość
teoretyczna, dyskusja) oraz porównać wyniki z zadaniem
A.
Prosty przykład znajduje się tutaj
- W większości zadań nie jest określony typ danych elementów zbioru. Można korzystać na przykład z liczb całkowitych.
Zestaw 4
Proszę zaimplementować ADT graph, który dla grafu \(G\) oraz wierzchołków \(x\), \(y\) ma implementacje następujących operacji:
- \(\text{adjacent}(G , x , y)\) - sprawdzanie, czy istnieje krawędź pomiędzy \(x\) oraz \(y\)
- \(\text{neighbours}(G , x)\) - zwracja sąsiadów \(x\)
- \(\text{addVertex}(G , x)\) - dodaje \(x\) do \(G\)
- \(\text{removeVertex}(G , x)\) - usuwa \(x\) z \(G\)
- \(\text{addEdge}(G , x , y)\) - dodaje krawędź pomiędzy \(x\) i \(y\)
- \(\text{removeEdge}(G , x , y)\) - usuwa krawędź pomiędzy \(x\) i \(y\)
- \(\text{getVertexValue}(G , x)\) - zwraca wartość skojarzoną z \(x\)
- \(\text{setVertexValue}(G , x , v)\) - kojarzy vartość \(v\) z wierchołkiem \(x\)
- \(\text{getEdgeValue}(G , x , y)\) - zwraca wartość skojarzoną z krawędzią pomiędzy \(x\) oraz \(y\)
- \(\text{setEdgeValue}(G , x , y , v)\) - kojarzy vartość \(v\) z krawędzią pomiędzy \(x\) oraz \(y\)
Państwa implementację proszę, na początek, oprzeć ma macierzy połączeń. Dodatkowo proszę zbadać złożoność jednej wybranej operacji (wykres oraz opis).
Zestaw 5
Proszę zapoznać się z pakietem Graphviz. Następnie korzystając z programu dot proszę stworzyć plik jpg z grafem:
- zawierającym trzy wierzchołki
- zawierającym połączenia, w obydwu kierunkach, pomiędzy wszystkimi wierzchołkami
Przykładowy plik z prostrzym grafem oraz rezultat. Aby stworzyć obrazek wystarczy w linii komend uruchomić:
{kind=link}
$ dot -Tjpg smallGraph -o smallGraph.jpgTutaj można znaleźć przewodnik po programie dot.
Proszę uzupełnić Państwa implementację grafu z poprzedniego zestawu o metodę tworzącą plik, który może być wykorzystany przez program dot do narysowania grafu.
Proszę zaimplementować ADT graph, posiadający wszystkie operacje z zadania A w zestawie 4. Tym razem proszę wykorzystać reprezentację w której dla każdego wierzchołka przechowywana jest list sąsiadów. Sprawdzić złożoność obliczeniową wybranej operacji i porównać z zadaniem A zestawu 4.
Proszę się zastanowić jak wykorzystać reprezentację grafową do rozwiązania problemu znalezienia minimalnej liczby “faz” sygnalizacji świetlnej na skrzyżowaniu:

Sygnalizacja świetlna w każdej “fazie” powinna zezwalać na ruch przez skrzyżowanie jedynie tym samochodom, których trajektorie nie będą się przecinać. Aby usprawnić działanie skrzyżowania, liczba tych etapów powinna być jak najmniejsza.
Wykorzystując jedną z napisanych przez Państwa implementacji grafów oraz zadanie A z poprzedniego zestawu proszę narysować reprezentację grafową takiego skrzyżowania.
Wskazówka: proszę zajrzeć na początek źródła.
Korzystając wyników zadania D, proszę napisać program minimalizujący liczbę “faz” sygnalizacji świetlnej dla tego skrzyżowania.
Wskazówki:
- Przykładowa implementacja algorytmu kolorującego jest dostępna tutaj
- Proszę zajrzeć na początek źródła.
Zestaw 6
Na szachownicy, na określonej pozycji, znajduje się pojedyncza figura - skoczek (koń). Proszę znaleźć taką trasę skoczka po szachownicy, aby każde pole było odwiedzone jedynie raz. Można wykorzystać jedną z wcześniej zaimplementowanych przez Państwa reprezentacji grafu lub skorzystać z gotowych bibliotek. Państwa wynik końcowy proszę przedstawić w formie rysunku.
Bierzemy udział w grze, która ma następujęce reguły:
startuje się z czteroliterowego wyrazu w języku polskim, na przykład “ster”
gra składa się z iteracji, w każdej iteracji można zmienić jedną literę czteroliterowego wyrazu ale pod warunkiem, że orzymane słowo istnieje w słowniku języka polskiego
gra kończy się gdy w wynku tych transformacji otrzyma się pewne, z góry ustalone słowo końcowe, na przykład “atom”
wygrywa osoba, która zamieni słowo startowe na słowo końcowe za pomocą najmniejszej liczny operacji
Jeżeli za słowo startowe wybierze się “ster” a za końcowe “atom” gra może wyglądać następująco:
ster -> step -> stop -> utop -> utom -> atomProszę zaimplementować program, szukający najkrótszej ścieżki pomiędzy zadanym słowem startowym i końcowym.
Wskazówka: Proszę zajrzeć do źródła. Słownik języka polskiego, w postaci spakowanego pliku tekstowego, można pobrać tutaj.
Robimy naleśniki. Składniki są następujące:
\(1\) jajko
\(1\) łyżka oleju
\(\frac{3}{4}\) szklanki mleka
\(1\) szklanka proszku do naleśników
syrop klonowy
patelnia
Abu zrobić naleśniki należy:
nagrzać patelnię
zmieszać jajko, olej, mleko i proszek do naleśników
wylać część ciasta naleśnikowego na gorącą patelnię
gdy naleśnik jest rumiany od spodu należy przewrócić i podpiec z drugiej strony
podgrzać syrop klonowy
zjeść rumiany (z obydwu stron) naleśnik polany ciepłym syropem klonowym
Proszę zareprezentować ten proces w postaci grafu \(G\). Następnie proszę napisać program, który na podstawie grafu \(G\) decyduje o kolejności wykonywanych czynności kulinarnych. Proszę uogólnić swój program, tak aby przyjmował dowolny graf \(G\).
Wskazówka: źródło.
- przykład
algorytmów BFS oraz DFS
- aby włączyć / wyłączyć pogląd kodu można nacisnąć
c
- aby włączyć / wyłączyć pogląd kodu można nacisnąć
Zestaw 7
Pracujecie Państwo w budynku biurowym w którym plan elewacji wygląda następująco:
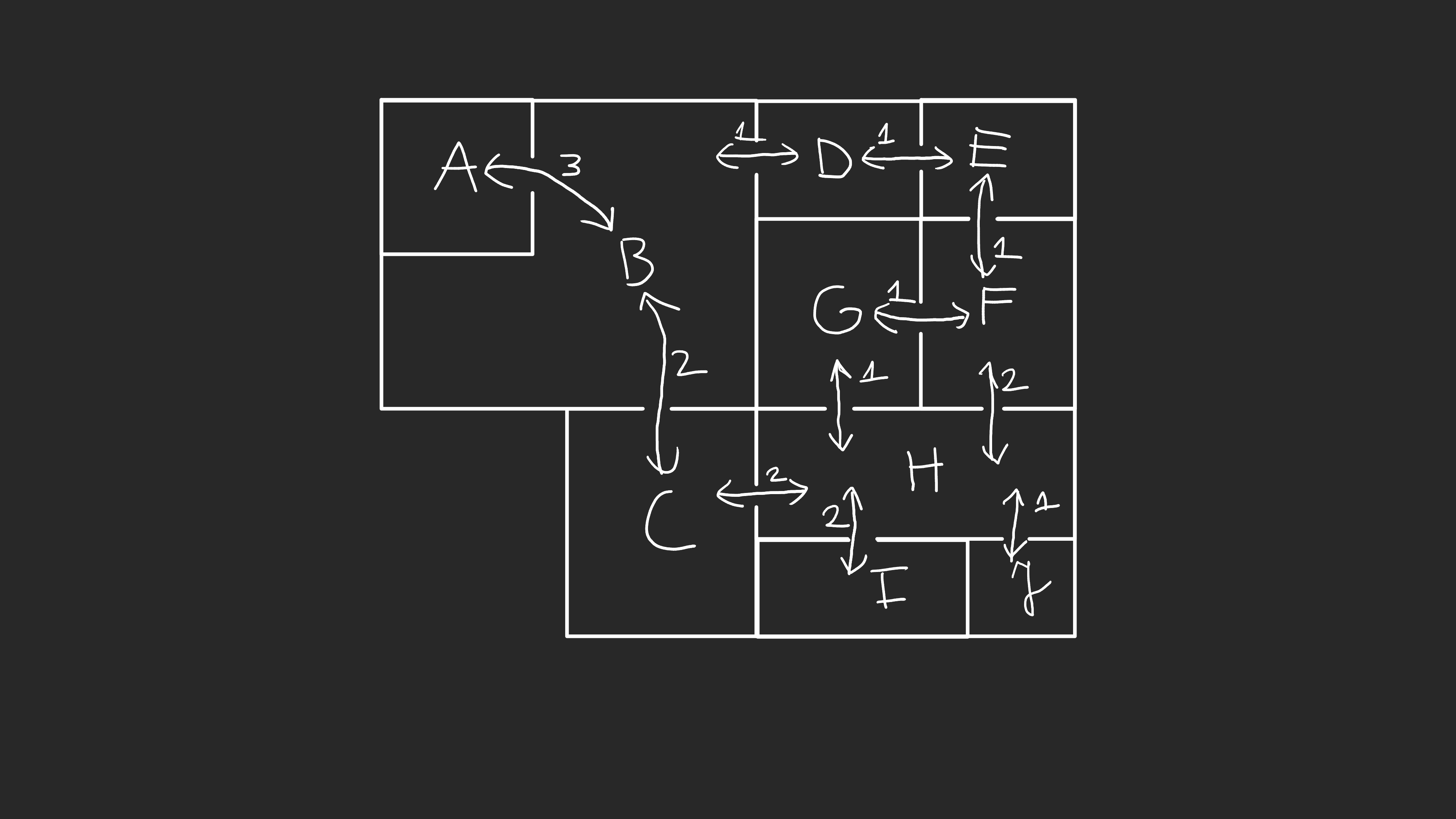
Korzystając z algorytmu Dijkstry proszę znaleźć najkrótszy czas przejścia z każdego pomieszczenia do klatki chodowej A oraz do ubikacji J. Liczby znajdujące się na strzałeczkach oznaczają średni czas potrzebny na przejęcie z jednego pomieszczenia do drugiego.
Praca biurowa wzmaga apetyt. Korzystając z algorytmu Dijkstry oraz planu elewacji z zadania A proszę znaleźć najkrótszą ścieżkę z aneksu kuchennego I do pokoju szefa D.
- przykład
- aby włączyć / wyłączyć pogląd kodu można nacisnąć
c
- aby włączyć / wyłączyć pogląd kodu można nacisnąć
Zestaw 8
Średnie czasy przejazdu samochodem pomiędzy polskimi miastami można odczytać z tabelki (dane pochodzą z google maps). W pierwszych dwóch kolumnach znajdują się miasta a w trzeciej kolumnie znajduje się czas przejazdu w minutach. Proszę znaleźć najkrótszy czas przejazdu pomiędzy wszystkimi parami miast. Wynik powinien być w postaci tabeli, której wiersze oraz kolumny odpowiadają kolejnym miastom natomiast wartości tabelki odpowiadają najkrótszym czasom przejazdu.
Wskazówka:
- Proszę skorzystać z algorytmu Floyda Warszalla.
- Można zajrzeć tutaj.
Korzystająć z tabelki czasów przejazdu (dane pochodzą z google maps) proszę znaleźć najszybszą trasę pomiędzy wszystkimi parami miast. Korzystając z programu dot (lub innego programu) oraz tabelki ze współrzędnymi geograficznymi miast (pierwsza kolumna zawiera nazwę miasta, druga oraz trzecia kolumna zawiera współrzędne geograficzne) proszę zaznaczyć na grafie wszystkie miasta oraz najszybsze trasy pomiędzy parami miast (jeden rysunek dla każdej pary).
Wskazówka 1: proszę skorzystać z algorytmu Floyda Warszalla.
Wskazówka 2: Przykładowy plik
do programu dot gdzie podane są współrzędne wierzchołków. Wykonanie
polecenia [źródło]dot -Kfdp -n -Tpng example_dot -o example_dot.png
powinno skutkować stworzeniem pliku.
{kind=link}
Zestaw 9
Prowadzicie Państwo serwis internetowy zapewniający dostęp do gier za pośrednictwem strumienia danych. Gry są uruchamiane na serwerach w waszej firmie i chcecie rozsyłać obraz oraz dźwięk do swoich użytkowników z jak najmniejszym opóźnieniem. Zbadaliście sieć połączeń pomiędzy waszą firmą oraz komputerami \(127\) klientów (jesteście raczkującą firmą) oraz zapisaliście ją w pliku. Pierwsze dwie kolumny zawierają indywidualne numery komputerów (numer \(1\) to wasza firma, numery \(2 \ldots 128\) to komputery klientów) pomiędzy, którymi są połączenia. Trzecia kolumna zawiera średnie opóźnienie sygnału z danymi dla danego połączenia. Aby znaleźć optymalną ścieżkę sygnału z danymi od waszej firmy (numerek \(1\)) do klientów należy skonstruować minimalne drzewo rozpinające graf połączeń. Proszę korzystając z algorytmu Prima policzyć takie drzewo. Wskazówka.
Proszę znaleźć drzewko z poprzedniego zadania korzystając z algorytmu Kruskala. Proszę porównać efektywność obydwu algorytmów. Wskazówka
Zestaw 10
[żródło] W pliku, pliku oraz pliku zapisane są grafy (skierowane oraz nie skierowane) w postaci macierzowej (1 - oznacza istninie krawędzi). Proszę napisać program badający cykliczność grafów i wykorzystać go do zbadanie tych trzech przykładów. Wskazówka.
W pliku, pliku oraz pliku zapisane są grafy (skierowane oraz nie skierowane) w postaci macierzowej (1 - oznacza istninie krawędzi). Proszę napisać program badający spójność grafów i wykorzystać go do zbadanie tych trzech przykładów. Wskazówka.